Bayes through the Looking-Glass: Assessing the Credibility of Clinical Trial Outcomes by Inverting Bayes’s Theorem

A trial reports p = 0.03. As this is less than 0.05, it meets the well-known criterion for being statistically significant. But is the trial outcome also credible? That depends on what you mean by credible—and on information the p-value alone cannot provide. Statistical significance tells you the data are unlikely under the null. It tells you nothing about whether the effect estimate can withstand reasonable skepticism, whether the effect size is plausible given what was already known, or whether a regulator should act on it. In fact, under the Reverse-Bayes framework described below, a finding needs a p-value around 0.0056 (not 0.05) to be considered intrinsically credible at the conventional 5% level. By that standard, p = 0.03 is not self-evidently convincing at all.
Reverse-Bayes methods turn that vague unease about mildly statistically significant outcomes into something sharper. As the name suggests, these methods invert the standard use of Bayes’s theorem. Instead of starting with a prior level of belief in effectiveness and combining it with the data to update that belief, Reverse-Bayes methods assess credibility by answering a different question: given the outcome obtained, what level of prior evidence would need to exist for this result to be credible as well as statistically significant?
That reframing sits at the heart of a methodological framework that has been developing in the background for two decades, one that may finally offer the statistical community a pragmatic path beyond the well-documented failures of null hypothesis significance testing (NHST). The most prominent form of Reverse-Bayes methods — the Analysis of Credibility (AnCred) — represents a compelling case for how Bayesian thinking can enhance, rather than replace, the frequentist toolkit that dominates clinical trial reporting.
Reverse-Bayes methods do not replace p-values. They reveal what p-values cannot tell you: how much prior skepticism a finding can withstand.
Importantly, this isn't about choosing a correct prior. It's about quantifying what kinds of skepticism the data can, or cannot, overcome. The reversal is not anti-Bayesian. It is a Bayesian diagnostic maneuver: reframing disagreement from "whose prior?" to "what prior is required for your conclusion?"—a dispute that is often more transparent and empirically tethered.
The Problem: Statistical Significance Is Not Credibility
The problems with p-values are no longer controversial. They're familiar. The 2016 ASA statement confirmed what methodologists had been arguing for decades: p-values are routinely misused and misinterpreted, and statistical significance at the p < 0.05 level bears no simple relationship to effect size, evidential weight, or the plausibility of a finding.
Yet the ASA statement stopped short of concrete recommendations. It called for researchers to move toward a "post p < 0.05 era," but offered no consensus on how. The result has been a proliferation of proposals (redefine the threshold to 0.005, report Bayes factors, abandon hypothesis testing altogether), none of which has achieved broad uptake.
The inertia is easy to explain. As Robert Matthews argued in his 2001 JSPI paper, the standard Bayesian critique of frequentist methods, while technically correct, has failed to provide working researchers with a cost-benefit case compelling enough to justify the investment in new methodology. The failings of p-values, though real, typically manifest not as dramatic inferential catastrophes but as subtle distortions that can be blamed on confounding, bias, or other factors. Meanwhile, the "cost" side of adopting full Bayesian analysis (specifying priors, defending subjective choices, learning new computational tools) remains formidable.
And even when researchers do adopt confidence intervals as recommended, they often revert to the same dichotomy: checking whether the likelihood excludes the null and stopping there. The AnCred framework is designed to extract additional interpretive content from the CI beyond that binary check—translating "how far and how precisely" into "how much skepticism is defensible."
What has been needed is a technique that adds genuine inferential value to the familiar summary statistics of clinical trials (point estimates and confidence intervals), without demanding that researchers abandon their existing workflow or acquire deep Bayesian expertise. This is precisely what Reverse-Bayes methods provide.
The Key Insight: Inverting Bayes' Theorem
The intellectual origin of Reverse-Bayes methods traces back to I.J. Good's 1950 monograph Probability and the Weighing of Evidence. Good described what he called the "device of imaginary results": instead of starting with a prior and updating forward, one imagines a result that would persuade you past some threshold, and then solves backward for what the prior must have been to make that persuasion possible. In modern terms, this is a direct early articulation of "Bayes' theorem in reverse," explicitly motivated by the practical difficulty of pinning down precise prior probabilities in contentious settings.
Both Good and E.T. Jaynes recognized the potential of this reversal for situations where specifying a prior is contentious. If sceptics and advocates of a hypothesis cannot agree on a prior, Reverse-Bayes methods can at least tell both sides what priors would be required to sustain their respective positions. The plausibility of those priors then becomes the focus of debate, a far more productive discussion than the usual standoff over whose subjective beliefs are more legitimate.
Despite this endorsement from two towering figures in Bayesian methodology, Reverse-Bayes methods remained largely unexplored until Matthews revived them in the context of clinical trial assessment around 2001. The subsequent two decades have seen a steady elaboration of the framework, culminating in a comprehensive review by Held, Matthews, Ott, and Pawel (2022) in Research Synthesis Methods that extends the approach to Bayes factors, false positive risk, meta-analysis, and replication.
The Critical Prior Interval and the Analysis of Credibility
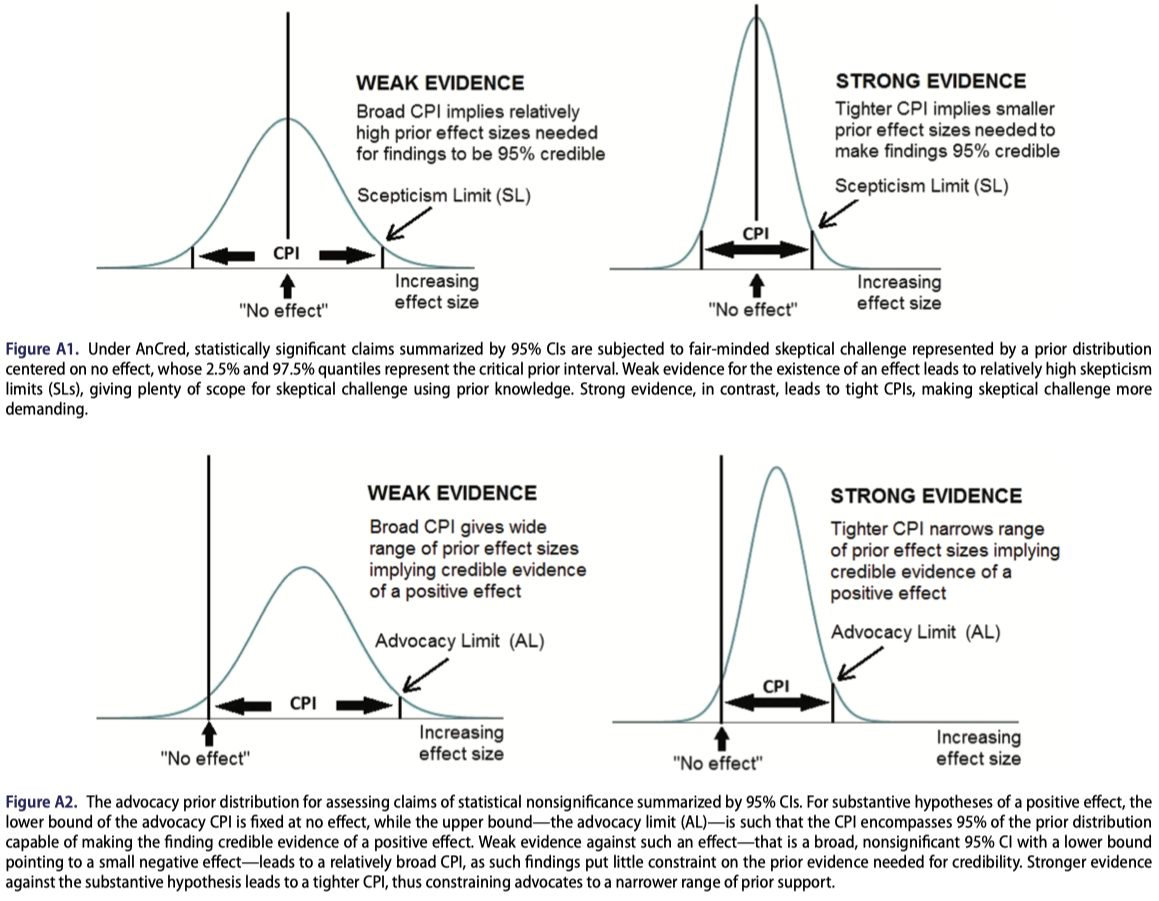
The core applied tool to emerge from Reverse-Bayes methodology is the Critical Prior Interval (CPI). The idea is straightforward. Suppose a clinical trial reports an odds ratio with a 95% confidence interval. Standard practice checks whether the CI excludes values implying no effect — e.g. 0 for difference of effects between groups, or 1 for ratios of effects and declares the result “significant” or not. The CPI asks a different question: what range of prior beliefs about the effect size, when combined with the observed likelihood via Bayes’ theorem, would produce a posterior credible interval that just barely includes the null?
In other words, the CPI delineates the boundary between prior beliefs that render the finding credible and those that do not. If a clinician's or reviewer's prior knowledge places plausible effect sizes outside the CPI, the finding may be regarded as credible at the stated level. If their prior knowledge falls within the CPI, the data lack the evidential weight to overcome prior skepticism.
For statistically significant findings, the CPI, calculated from the likelihood, takes the form of a prior distribution whose peak lies at the value corresponding to no effect, and whose tails are symmetric about this value — representing “fair-minded scepticism” about the credibility of the finding. Specifically, the CPI scepticism limit (SL): the minimum effect size that a sceptic must already consider plausible in order for the significant result to be deemed credible. A large SL implies that only those who already believed in a dramatic effect would find the data convincing, a clear signal that the evidence is weak despite its nominal significance.
For statistically nonsignificant findings, the CPI, calculated from the likelihood, instead yields an advocacy limit (AL): the maximum effect size that an advocate of the hypothesis can claim is supported by the data. A modest AL indicates that even a partisan reading of the evidence cannot rescue a large effect, while a large AL suggests the data are simply too weak to be informative in either direction.
A natural question arises from the scepticism limit: at what point does a finding become self-evidently credible — credible in the sense of being incompatible with the sceptical prior capable of undermining its credibility? Held (2021, §2.2) uses Box’s theory of prior-data conflict to show that this occurs this occurs for a result with a p-value less than 0.0056 — considerably stricter than the conventional 0.05 threshold. A finding satisfying this condition is termed intrinsically credible. It is this result that motivates the observation that p ≈ 0.005, not p = 0.05, is where statistical significance and genuine credibility begin to align. The Bayes-factor extension of AnCred, discussed in the section below, arrives at the same threshold via an independent mathematical route — providing additional confidence in the result.
How to use CPI in practice (30 seconds):
If the result is significant: compute the scepticism limit. If it implies an implausibly large effect is needed to stay "credible," treat the finding as fragile.
If the result is nonsignificant: compute the advocacy limit. If it still allows clinically meaningful effects, don't claim "no effect." Claim "uninformative."
The mathematical derivations assume normal distributions for the likelihood and prior. In what follows, L and U denote the conventional lower and upper bounds of the 95% CI used to summarise the outcome of an experiment. For example, they could represent the bounds of the difference between the effect on two groups, or the log of the Odds Ratio (OR) or Hazard Ratio (HR), which are commonly-used measures of effects in clinical trials (we simply exponentiate the resulting limits to return to the OR/HR scale). For a statistically significant finding, the scepticism limit is:
$$\text{SL} = \frac{(U - L)^2}{4\sqrt{UL}}$$
and for nonsignificant findings, the advocacy limit is:
$$\text{AL} = -\frac{(U + L)}{2UL}(U - L)^2$$
These expressions encode a crucial feature: the CPI depends not merely on whether the CI excludes the null, but on the width and location of the CI relative to the null. Two findings with identical p-values can have very different CPIs if their confidence intervals differ in width, directly reflecting their different evidential weights.
The geometric intuition is useful here. The CPI reflects how far the confidence interval sits from the null relative to its width. A narrow CI far from the null produces a tight CPI, one that demands little prior conviction to find credible. A wide CI barely excluding the null produces a demanding scepticism limit, requiring strong prior belief to take the result seriously.
Clinical Trial Examples: Where Significance and Credibility Diverge
Here's what it looks like when significance and credibility diverge in real trials.
The GREAT trial (1992). This study of early anistreplase for acute myocardial infarction reported an impressive OR of 0.47 (95% CI: 0.23, 0.97), statistically significant at p ≈ 0.04, suggesting that early administration halved mortality. Pocock and Spiegelhalter showed via a conventional Bayesian analysis that combining this result with a plausible prior interval yielded a far more modest posterior OR of approximately 0.73 (posterior interval roughly 0.6–0.9). The CPI makes the same point more transparently. The scepticism limit implies that the finding is credible only if one already believed that giving anistreplase two hours earlier could produce a 90% mortality reduction.
Subsequent JAMA meta-analysis of prehospital thrombolysis confirmed a much more modest pooled effect (OR 0.83, 95% CI: 0.70–0.98), vindicating the skepticism that the CPI formalized.
The RECOVERY trial (2020). In contrast, the RECOVERY trial's finding on corticosteroids and COVID-19 mortality (log-OR = −0.53, 95% CI: −0.82 to −0.25) yields a scepticism limit of 0.18 on the log-odds scale, corresponding to a critical prior interval with bounds of roughly 0.84 and 1.19 on the OR scale. This is a relatively tight CPI, meaning sceptics would need to believe that mortality reductions (in terms of odds) are unlikely to exceed about 16% in order to dismiss the finding. Given the plausible mechanism and emerging clinical evidence at the time, this is a demanding position for sceptics to maintain. The RECOVERY result is thus both statistically significant and credible, and is also intrinsically credible (p = 0.002 < 0.0056). This was later confirmed by the dramatic effectiveness of corticosteroids in saving lives.
Subcutaneous sumatriptan for migraine. An early study with only ~100 patients per arm reported a striking OR of 11.4 (95% CI: 6.00, 21.5) for symptom improvement. The small sample yields a broad CI, yet the effect is so large that the CPI is just (1.00, 1.20), credible unless one deems even a 20% efficacy implausible. This example counters the concern that AnCred automatically penalizes small studies. The actual claim is subtler: low precision invites skepticism, but a huge effect can still be credible if the likelihood is far enough from the null to constrain the CPI.
The ORBITA trial (2018). This sham-controlled trial of stents for stable angina found a nonsignificant difference in exercise time (+16.6 sec, 95% CI: −8.9, 42.0, p = 0.200). The standard interpretation was that stents provide no benefit, prompting calls to revise cardiology guidelines. AnCred tells a more nuanced story: the advocacy limit is +115 seconds, meaning the data are consistent with a positive effect as large as 115 seconds. The nonsignificance here reflects weak evidential weight (broad CI from ~200 patients), not strong evidence of no effect. The appropriate response to this non-significant outcome should have been that the trial was too weak to reach a compelling answer either way, not that stents were useless.
Beyond Credible Intervals: Reverse-Bayes with Bayes Factors
For readers interested in hypothesis testing rather than estimation, Held et al. (2022) extend the Reverse-Bayes framework to Bayes factors. Rather than determining a prior such that the posterior just includes zero, this approach determines the prior variance g (relative to the observational variance) such that the Bayes factor BF₀₁ reaches a chosen threshold γ (e.g., 1/10 for "strong evidence" in Jeffreys' classification).
This extension has several advantages. It connects naturally to the well-developed theory of Bayes factors for evidence quantification. It also independently corroborates intrinsic credibility, introduced above from the scepticism limit geometry: the BF-based derivation arrives at the same p ≈ 0.0056 threshold via a distinct mathematical route, offering additional confidence in the result.
A technical consequence worth noting: in the Bayes-factor formulation, an "advocacy prior" capable of making weak data into "strong evidence" may not exist beyond the minimum Bayes factor bound. This is unlike traditional credible-interval AnCred, where some advocacy prior can always be found. The Bayes-factor version is stricter.
The Bayes factor formulation also provides a principled approach to false positive risk (FPR). Using Reverse-Bayes, one can determine what prior probability of the null hypothesis Pr(H₀) is needed to achieve a specified FPR given an observed p-value. This makes explicit the often-unrecognized dependence of false positive risk on prior beliefs—a point obscured by the standard p-value framework, and one that undercuts the common conflation of FPR = 5% with Type I error = 5%.
Connections to Meta-Analysis and Replication
Reverse-Bayes methods integrate naturally with meta-analysis. In a fixed-effect meta-analysis, the pooled estimate represents iterated Bayesian updating starting from a flat prior. The Reverse-Bayes inversion allows one to compute the prior that would exist after removing any single study (the leave-one-out prior) and assess whether that study's contribution is consistent with the rest of the evidence via prior-predictive checks (the Box prior-predictive p-value).
The framework also speaks to the replication crisis. The p-value for intrinsic credibility, p_IC, is connected to the probability that a replication will produce an effect estimate in the same direction as the original. An intrinsically credible finding at a small α has a high probability of directional replication, while a finding that fails intrinsic credibility has at best a coin-flip chance. This provides a defensible bridge from "credibility" to "replicability" without invoking the overpromised idea that p < 0.05 guarantees replication.
The "equivalent prior study" representation provides further intuition: the sceptical prior can be expressed as a hypothetical prior study with a specific number of events and non-events. For the RECOVERY trial, the sceptical prior is equivalent to a study with 389 events and 648 non-events in each arm, more than twice the size of RECOVERY itself. The fact that even a study of this magnitude would not render the RECOVERY finding non-credible underscores the strength of the evidence.
Why This Matters for Regulatory Decision-Making
For practising statisticians evaluating clinical trial evidence, Reverse-Bayes methods offer several concrete advantages over both standard NHST and full Bayesian analysis.
The framework works with the existing reporting infrastructure. It takes as input the standard summary statistics (point estimates and confidence intervals) that every trial already reports. No redesign of trial reporting is required. It sidesteps the problem of priors by making the prior the output rather than the input of the analysis. This eliminates the most contentious aspect of Bayesian inference while retaining its core inferential strengths: the ability to set findings in context, to distinguish evidential weight from statistical significance, and to produce probability statements with straightforward interpretations.
It provides protection against several well-documented inferential fallacies: the confusion of statistical significance with practical importance, the misinterpretation of nonsignificance as evidence of no effect, the retrospective misuse of statistical power, and the treatment of "discordant" studies (one significant, one not) as contradictory.
And the CPI framework scales naturally with sample size. Large, well-powered trials produce tight CPIs that are difficult for sceptics to dismiss; small, underpowered trials produce broad CPIs that temper enthusiasm regardless of headline p-values. This encodes the common-sense intuition that larger studies should be more convincing, without falling into the power fallacy (the mistaken belief that small studies are necessarily less compelling than large ones).
But the deeper relevance is regulatory. On January 12, 2026, the FDA published draft guidance titled Use of Bayesian Methodology in Clinical Trials of Drug and Biological Products, describing appropriate use of Bayesian methods to support primary inference in clinical trials for drugs and biologics. In that context, Reverse-Bayes methods can function as a communication bridge: even when full Bayesian primary inference uses an explicit prior, reviewers and stakeholders can still ask, "What skepticism must be assumed to undermine the credibility of this result?" That is CPI language. In practice, regulators often ask a Reverse-Bayes question without naming it: is this estimate strong enough to overcome reasonable skepticism? AnCred makes that implicit question explicit—and quantifiable.
Looking Forward
The appeal of Reverse-Bayes techniques has widened considerably in recent years with the development of inferential methods using both posterior probabilities and Bayes factors. All analyses can be performed in R using the pCalibrate package, and the code for the COVID-19 meta-analysis example is publicly available (https://gitlab.uzh.ch/samuel.pawel/Reverse-Bayes-Code).
AnCred is not a panacea. It relies on normal approximations, symmetric priors centered on no effect, and the assumption that the reported CI adequately captures the uncertainty in the data. It does not protect against confounding, publication bias, or data fabrication. But it does something that no amount of p-value reform can accomplish on its own: it compels researchers to state explicitly what they must believe in order to find a result convincing, and it provides a quantitative, transparent basis for that conversation.
Reverse-Bayes methods don't abolish thresholds. They relocate the argument. Not "Is p < 0.05?" but "What would you need to believe for this to be convincing?" That question is harder to game, and harder to ignore.
Acknowledgement
With contributions and editorial feedback from Robert A.J. Matthews, Department of Mathematics, Aston University, whose foundational work on AnCred is the subject of the piece.

References
- Good, I.J. (1950). Probability and the Weighing of Evidence. London: Charles Griffin.
- Matthews, R.A.J. (2001). Methods for assessing the credibility of clinical trial outcomes. Drug Information Journal, 35, 1469–1478.
- Matthews, R.A.J. (2001). Why should clinicians care about Bayesian methods? Journal of Statistical Planning and Inference, 94, 43–58.
- Matthews, R.A.J. (2019). Moving towards the post p < 0.05 era via the analysis of credibility. The American Statistician, 73(sup1), 202–212.
- Held, L. (2019). The assessment of intrinsic credibility and a new argument for p < 0.005. Royal Society Open Science, 6(3), 181534.
- Held, L., Matthews, R., Ott, M., & Pawel, S. (2022). Reverse-Bayes methods for evidence assessment and research synthesis. Research Synthesis Methods, 13(3), 295–314.
- Wasserstein, R.L. & Lazar, N.A. (2016). The ASA statement on p-values: context, process, and purpose. The American Statistician, 70(2), 129–133.
- Al-Lamee, R. et al. (2018). Percutaneous coronary intervention in stable angina (ORBITA): a double-blind, randomised controlled trial. The Lancet, 391(10115), 31–40.
Member discussion